
EP3:AI 時代下,人人都該自帶的數據分析技能
📰 Data + AI = ∞ 每週分享我在資料科學與人工智慧領域上觀察的趨勢發展與所見所聞

嗨,你好,我是維元 👋 我將在 📰 Data + AI = ∞ 分享我在資料科學與人工智慧領域上觀察的趨勢發展與所見所聞 💥 經歷上午地震、一整天的會議,最後在趕上連假的返鄉車潮,你今天(這週)過得如何呢?希望大家一切安好 🙏
本期內容搶先看
AI 時代下,人人都該自帶的數據分析技能
Data/AI 趨勢熱點
你有自架 LLM 的需求嗎?開源、輕量級 LLM 正在崛起
你的聲音不是你的聲音,Voice Engine 語音生成模型
xAI 的開源模型超英趕美:Grok-1 → Grok-1.5
趕在 Sora 前卡位,StreamingT2V 生成 120 秒影片
反歧視!IEEE 期刊宣布不接受 Lenna 圖稿
LLM 新玩家參戰: DBRX、Samba-CoE、ReALM
資料科學領域的你問我答
AI 時代下,人人都該自帶的數據分析技能
⚡ 全新 Podcast 節目 🎧 資料工作者的下班幹話群 將於每週一同步發布。
今天想與大家分享的主題是「AI 時代下,人人都該自帶的數據分析技能」,以前我們會用「分析」、「工程」或「科學」三種角色區分資料科學團隊。不過隨著 AI 技術逐漸成熟的情況下,我常常說過去十年是基礎建設時期是那些資料科學家的努力,而當 AI 工具到位的未來十年則是這些資料使用者的主場。如同我們上一集提到的「資料分析不死,會轉身為人人都需要擁有的數據分析力」那這個數據分析是究竟是什麼呢?
我自己會定位成兩個面向:1. 更深的領域知識經驗 2. 更準的資料驅動觀點
⮑ 更多完整內容點擊收聽:🎧 資料工作者的下班幹話群
Data/AI 趨勢熱點
接下來的段落會回顧這一週看到的 Data/AI 趨勢與熱點觀察(會搭配下週的 Podcast 內容錄製),以下幾個主題是我關注到覺得不可錯過:
你有自架 LLM 的需求嗎?開源、輕量級 LLM 正在崛起
你的聲音不是你的聲音,Voice Engine 語音生成模型
xAI 的開源模型超英趕美:Grok-1 → Grok-1.5
趕在 Sora 前卡位,StreamingT2V 生成 120 秒影片
反歧視!IEEE 期刊宣布不接受 Lenna 圖稿
LLM 新玩家參戰: DBRX、Samba-CoE、ReALM
你有自架 LLM 的需求嗎?開源、輕量級 LLM 正在崛起
上週我們才介紹了 Mistral 7B v0.2 基礎模型的發布,這週在 Chatbot Arena 上關注到的是另一個輕量級語言模型 Starling-LM-7B-beta。這是由 UC berkeley 開發的開源大型語言模型,主要特色是 RLAIF(Reinforcement Learning from AI Feedback)功能,能夠從與人類交互中學習並改進,實現利用AI反饋結果進行增強式學習。
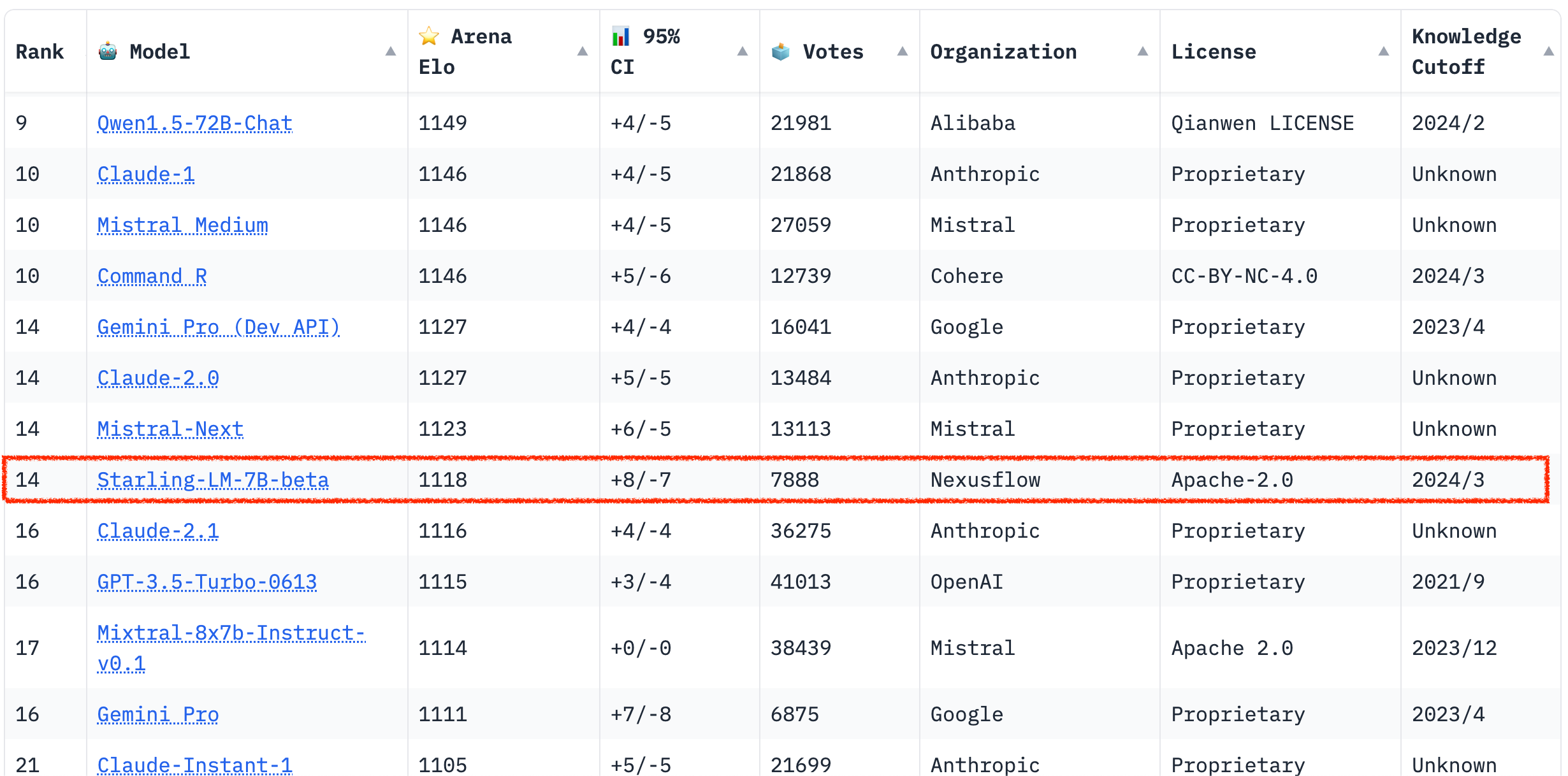
從結果來看使用者偏好排行榜看到 Starling-LM-7B-beta 目前暫居第 14 名(是 7B 模型中最受歡迎的),而上週提到的 Mistral-7B-Instruct-v0.2 則排在第34名,同時還超越了 GPT-3.5-Turbo、Gemini Pro 等更大的模型。這顯示出開源、輕量級的模型是一個值得關注的賽道,也意味著更多人正在嘗試選擇自建的 LLM。順帶一提,如果使用Ollama 部署的話僅需 4.1GB,相對來說這是一個較低的入門門檻。
你的聲音不是你的聲音,Voice Engine 語音生成模型
OpenAI 發布一個新的多模態模型 Voice Engine,提供約 15 秒的音檔後即可產生一個仿真的 AI. 人聲。Voice Engine 其實早在 2022 年底就已經開發,用於支援 ChatGPT 可以把文字內容唸出來。不過面對個資、版權紛爭的爭議,因此目前 Voice Engine 尚未有近一步的開放計劃。

AI. 人聲不是一個新的概念,之前蘋果在 iOS 17 也引入基於 AI 的新無障礙功能。其中 Personal Voice 能夠透過 15 分鐘的使用者音頻創建個人化的聲音,透過本地端的機器學習保護使用者隱私。並可以在通話中與 Live Speech 搭配使用,將文字直接轉成個人化的聲音輸出。
xAI 的開源模型超英趕美:Grok-1 → Grok-1.5
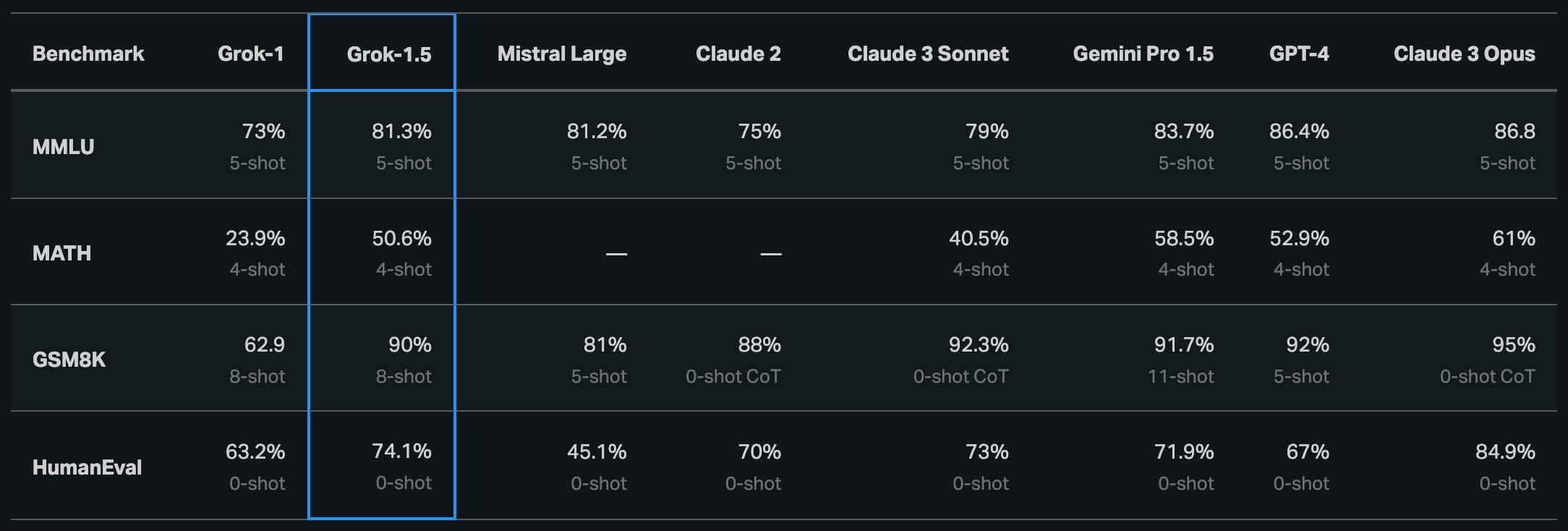
兩週前(上上一期電子報)才火速宣布及上架的 xAI 的開源模型 Grok-1,過沒幾天再度宣布 Grok-1.5 將於本週發布(原貼文在 3/29 表示下週將推出 Grok-1.5) 。官方的新聞稿中強調在許多基準測試表現上,Grok-1.5 已經能夠達到(接近)一線語言模型的水準,例如 GPT-4、Gemini Pro 1.5、Claude 3 Opus Anthropic。
趕在 Sora 前卡位,StreamingT2V 生成 120 秒影片
相信 OpenAI 的 Sora 是許多人期待的下一個 AI 里程碑,從 Pika、Runway 數秒鐘的影片到 60 秒的 Sora;StreamingT2 能夠生成 120 秒(甚至理論上更長)的影片,並且達到一致且流暢的影片。

反歧視!IEEE 期刊宣布不接受 Lenna 圖稿

如果你有修過或是研究電腦視覺/影像辨識的朋友,那你肯定看過這張圖 - Lenna。萊娜圖(Lenna)是一張大小為 512x512 像素的標準測試圖像,該圖在數位影像處理學習與研究中常被作為範例用於資料壓縮和降噪等例圖。不過你知道是真有其人嗎?圖中人為瑞典模特兒獲邀出席圖像科學學會的週年大會,由《花花公子》雜誌攝影師拍攝。由於女性歧視議題與尊重肖像權等爭議,IEEE 宣布 2024/04/01 後不在接受含有 Lenna 圖稿之論文。
LLM 新玩家參戰: DBRX、Samba-CoE、ReALM
蘋果在兩天前公佈名為 ReALM(Reference Resolution As Language Modeling)的 LLM 模型,能夠更好的對應理解前後文關係,在智慧型裝置上擁有比 GPT-4 更好的運算效能。相較於 Google 的 Gemini、微軟與 OpenAI 的 GPT-4,Apple 在 AI 模型上的應用相對較弱,甚至過去幾次的發表會上也盡量避開 AI 這個字。但實際上比較像是鴨子划水,許多論文持續在產出,例如 Ferret、MM1 到 ReALM;又或是上週傳出正在和 Google. 洽談在 iPhone 導入 Gemini 的可行性。

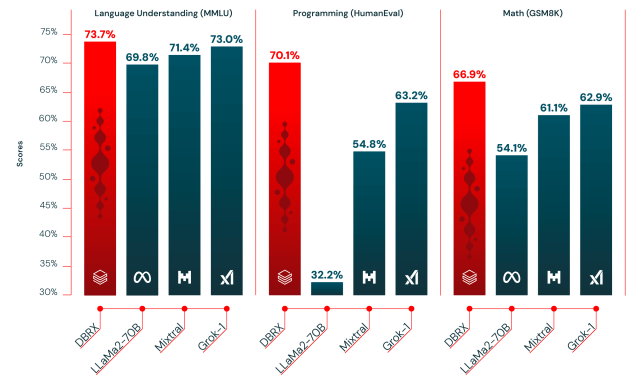
第二個看到的大型語言模型是由數據平台 Databricks 推出的 DBRX ,下圖的評測顯示在語言理解 (MMLU)、寫程式 (HumanEval) 和數學 (GSM8K) 方面超越了現有的開源模型。
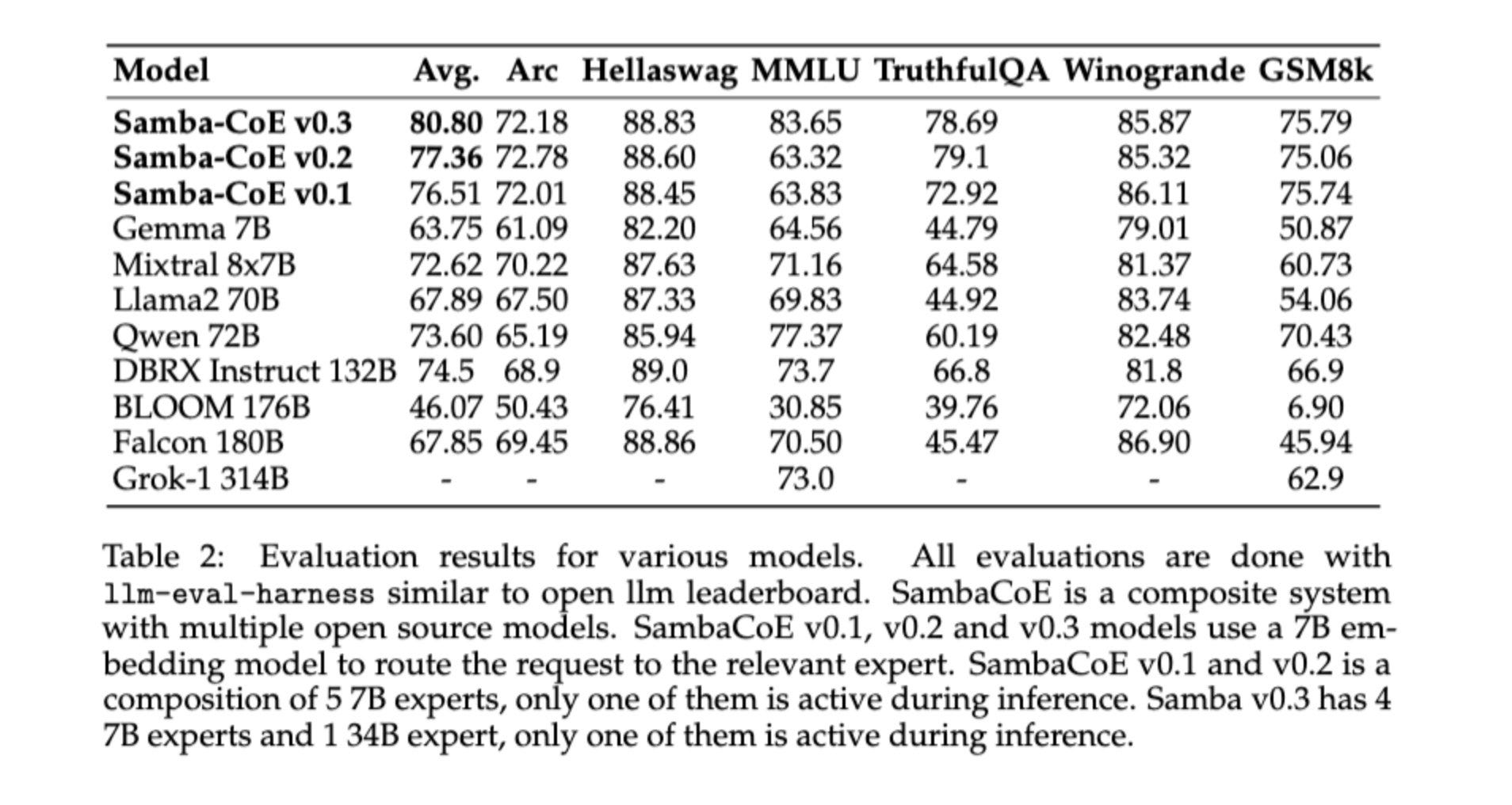
最後一個是 AI 晶片製造公司 SambaNova System 推出的的 Samba-CoE,主打的是每秒的處理速度提升字 330 個 tokens,比起近期的 Databricks DBRX、MistralAI 和 Grok-1 都來得快。
👇 如果你有發現什麼有趣的題目,也歡迎在底下留言跟我們分享 👇
資料科學領域的你問我答
最後一段搭配近期發起的社群挑戰「 #資料科學領域的你問我答 」,每週會在臉書粉專開啟話題,邀請你在這則貼文留言關於數據領域的各種好奇或疑問,我將在收單整理後分享我的觀點與經驗 😎
如何在面試時將跨領域此種特質轉變成優勢?
➟ 累積 domain knowledge (領域知識)+ 強調如何找出該領域資料能切入的點。
成為數據分析師專業的基礎能力可以從哪些開始培養?
➟ 可以先從訂閱我的社群「資料科學家的工作日常」和課程「Python 資料科學教學實戰營」開始。
請問這份工作上會有年齡限制嗎? 怎麼發現自己想做數據的工作呢?
➟ 沒有,不過你要思考對自己的限制;畢竟你身邊的朋友可以都已經往下一個階段前進的時候,你該如何歸零跟比自己小一輪學弟妹競爭,我覺得是心理上會比較卡的。
📰 Data + AI = ∞
📰 Data + AI = ∞ 會用兩個全新的渠道持續輸出我對資料科學 x 人工智慧領域的觀察與見解,邀請對該主題有興趣的朋友一起加入訂閱、關注 ✌️
⮑ 📰 Data + AI = ∞ 電子報 + 🎧 資料工作者的下班幹話群 Podcast